Async Agent Mesh with AWS SNS and SQS
Async Agent Mesh with AWS SNS and SQS
When two of your domain agents need to collaborate, HTTP callbacks are rarely enough. A planning agent might need to dispatch ten enrichment jobs, wait for partial completions, and still keep operating even if one downstream service is offline for a few minutes. That calls for asynchronous rails, and the most battle-tested rails in the cloud are Amazon Simple Notification Service (SNS) and Amazon Simple Queue Service (SQS). This article outlines how to use SNS fan-out topics and SQS worker queues so your AI agents exchange intents, events, and results reliably-without blocking on synchronous APIs.
Thesis: Treat SNS and SQS as the shared nervous system for agent workflows; let AWS AgentCore orchestrate messages on and off the bus while AWS guarantees durability, retries, and fan-out at scale.
Scenario: You operate AWS AgentCore, the managed orchestration fabric that sequences planning agents, enrichment bots, and review assistants. Product wants to add a lead-qualification agent that calls Salesforce, Marketing wants a content agent that posts to several blogs, and Compliance insists on durable audit logs. Rather than daisy-chain webhooks, you decide to build an async mesh with SNS topics for intent broadcasting, SQS queues for each worker fleet, and AWS AgentCore as the command brain routing missions. The rest of this guide walks through architecture, IAM, implementation in Node.js and Python, reliability add-ons, observability, and how AWS AgentCore fits in.
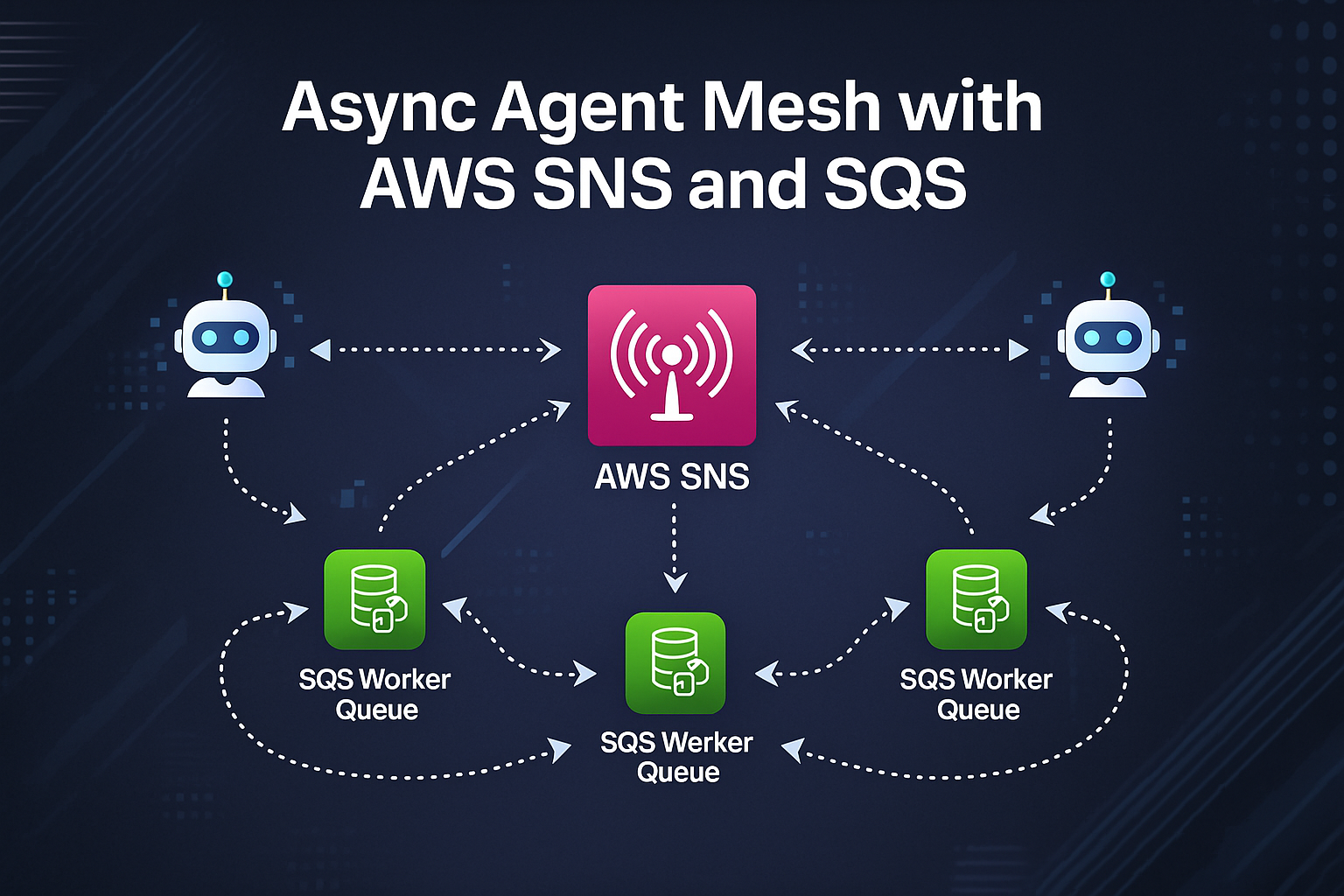
Architecture: SNS Fan-out Feeding SQS Worker Queues
Start with an SNS topic that represents a domain event such as agentcore.tasks. Planning agents publish intents (example: "enrich-prospect"), and each downstream capability subscribes via its own SQS queue. SNS guarantees at-least-once delivery and handles cross-region fan-out, while SQS provides per-consumer backpressure, visibility timeouts, and dead-letter queues (DLQs).
AWS AgentCore Planner
|
SNS Topic (agentcore.tasks)
/ \
SQS: enrichment SQS: reviewer
\ /
Agent Workers (Node + Python, autoscaled)
Key architectural decisions:
- Topic strategy: Use one topic per mission family (e.g.,
agentcore.tasks,agentcore.audit). Keep payloads under 256 KB; store large documents in S3 and send pointers. - Queue isolation: Give each worker fleet its own SQS queue, even if two fleets consume similar events, so a noisy consumer cannot starve the others.
- Ordering: For strict ordering per entity (like a single customer), use FIFO queues with
MessageGroupIdset to the entity ID. Otherwise, standard queues increase throughput. - Retry boundaries: SNS retries transient subscription failures, but SQS handles message-level retries via the visibility timeout. Combine both for layered resiliency.
Takeaway: SNS handles broadcast and fan-out; SQS encapsulates each worker's pacing and error handling. The combination yields loosely coupled agents that never wait on each other's HTTP endpoints.
IAM, Message Contracts, and Deployment Baseline
Before writing code, define the message contract and tighten permissions.
- Message contract: Use JSON with explicit schema fields so AWS AgentCore and workers remain compatible. Example:
{
"missionId": "msc_9ff12",
"origin": "planner",
"intent": "enrich-prospect",
"payload": {
"prospectId": "acme-203",
"priority": "high",
"callback": "https://agentcore/api/status/msc_9ff12"
},
"trace": {
"correlationId": "corr_7af2",
"modelVersion": "claude-3.5",
"issuedAt": "2025-11-21T14:32:01Z"
}
}
- IAM policies: Grant AWS AgentCore publish rights on the SNS topic, and grant each worker queue the permission to subscribe. Keep policies principle-of-least-privilege by referencing ARNs directly. Example CloudFormation snippet:
Resources:
AgentTasksTopic:
Type: AWS::SNS::Topic
Properties:
TopicName: agentcore-tasks
EnrichmentQueue:
Type: AWS::SQS::Queue
Properties:
QueueName: agentcore-enrichment
VisibilityTimeout: 60
KmsMasterKeyId: alias/aws/sqs
RedrivePolicy:
deadLetterTargetArn: !GetAtt EnrichmentDLQ.Arn
maxReceiveCount: 5
TopicToQueuePolicy:
Type: AWS::SQS::QueuePolicy
Properties:
Queues:
- !Ref EnrichmentQueue
PolicyDocument:
Statement:
- Sid: AllowTopicSend
Effect: Allow
Principal: "*"
Action: "sqs:SendMessage"
Resource: !GetAtt EnrichmentQueue.Arn
Condition:
ArnEquals:
aws:SourceArn: !Ref AgentTasksTopic
-
Infrastructure as code: Use CDK or Terraform so topics, queues, and DLQs stay consistent across staging and production. Reference: AWS SNS with SQS subscriptions.
-
Results topic + encryption: Most agent meshes also publish completion events back to AWS AgentCore via a results topic. Mirror the same IAM and policy structure, but grant only the worker fleet permission to publish. Example outputs block:
ResultsTopic:
Type: AWS::SNS::Topic
Properties:
TopicName: agentcore-results
KmsMasterKeyId: alias/aws/sns
ResultsPublisherRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Statement:
- Effect: Allow
Principal:
Service: ecs-tasks.amazonaws.com
Action: sts:AssumeRole
Policies:
- PolicyName: PublishResults
PolicyDocument:
Statement:
- Effect: Allow
Action: sns:Publish
Resource: !Ref ResultsTopic
When you enable server-side encryption, pair the SNS key with SQS-side encryption (KmsMasterKeyId) so mission payloads stay encrypted at rest across both services.
- IAM checklist:
- AgentCore runtime role:
sns:Publishon each tasks topic. - Worker queue policy: allow only the originating topic to send (
sqs:SendMessagewithaws:SourceArncondition). - Worker compute role:
sqs:ReceiveMessage,DeleteMessage,ChangeMessageVisibilityon its queue andsns:Publishon the results topic. - Results topic policy: allow only the worker role ARN to publish updates back to AgentCore.
- KMS key policy: grant both AgentCore and worker roles usage rights if you bring your own CMK instead of AWS-managed keys.
- AgentCore runtime role:
Takeaway: A clean contract plus minimal IAM scopes prevent mystery failures when AWS AgentCore or worker fleets evolve independently.
Publishing and Consuming Messages (Node.js and Python)
With the infrastructure live, implement publishing from AWS AgentCore and consumption inside your agent workers. The examples below use the AWS SDK for JavaScript (v3) and Python's boto3.
Publishing from AWS AgentCore (Node.js)
import { SNSClient, PublishCommand } from "@aws-sdk/client-sns";
const sns = new SNSClient({ region: "us-east-1" });
const topicArn = process.env.AGENT_TASKS_TOPIC_ARN;
export async function dispatchMission(mission) {
const payload = {
missionId: mission.id,
origin: "agentcore",
intent: mission.intent,
payload: mission.payload,
trace: {
correlationId: mission.correlationId,
modelVersion: mission.modelVersion,
issuedAt: new Date().toISOString()
}
};
await sns.send(
new PublishCommand({
TopicArn: topicArn,
Message: JSON.stringify(payload),
MessageAttributes: {
intent: { DataType: "String", StringValue: mission.intent },
priority: { DataType: "String", StringValue: mission.payload.priority }
}
})
);
}
Notes:
- Capture correlation IDs so you can thread logs later.
- Use message attributes for intent-based filtering or metrics in CloudWatch.
Consuming from SQS (Python worker)
import json
import os
import boto3
from botocore.exceptions import ClientError
sqs = boto3.client("sqs", region_name="us-east-1")
queue_url = os.environ["ENRICHMENT_QUEUE_URL"]
def handle_message(message):
body = json.loads(message["Body"])
payload = json.loads(body["Message"])
intent = payload["intent"]
if intent == "enrich-prospect":
run_enrichment(payload["payload"])
else:
raise ValueError(f"Unsupported intent {intent}")
def poll():
while True:
resp = sqs.receive_message(
QueueUrl=queue_url,
MaxNumberOfMessages=5,
WaitTimeSeconds=20
)
for msg in resp.get("Messages", []):
try:
handle_message(msg)
sqs.delete_message(
QueueUrl=queue_url,
ReceiptHandle=msg["ReceiptHandle"]
)
except Exception as exc:
print(f"Worker error: {exc}")
# Let visibility timeout expire so SQS retries
if __name__ == "__main__":
poll()
Implementation tips:
- When SNS delivers to SQS, the message body wraps the original payload. Parse twice (
msg["Body"]then["Message"]). - Use long polling (
WaitTimeSeconds=20) to reduce cost. - Delete messages only after successful handling.
Takeaway: Keep publishers and consumers boring and deterministic-the orchestration magic happens in AWS AgentCore, not in ad-hoc retry loops inside each worker.
Reliability Patterns: DLQs, Idempotency, and Backpressure
Asynchronous links buy resilience only if you plan for every failure mode.
-
Dead-letter queues: Configure each worker queue with a DLQ that captures messages after repeated failures (
maxReceiveCount). Monitor DLQ depth through CloudWatch alarms or AWS AgentCore dashboards, and provide a re-drive script to move fixed messages back into the main queue. -
Idempotency keys: Include
missionIdorcorrelationIdin every payload and ensure workers store processed IDs (Redis, DynamoDB). If SQS redelivers a message, the worker should skip duplicates. -
Visibility timeout tuning: Align the SQS visibility timeout with the longest processing task. If enrichment normally takes 20 seconds but can spike to 45, set the timeout to 60 and extend it via
ChangeMessageVisibilityfor edge cases. -
Backpressure: Auto Scale worker fleets (ECS, Lambda, Karpenter) based on queue depth metrics. For high-priority intents, consider separate queues so bursts do not overwhelm general-purpose workers.
-
Ordered workflows: When FIFO semantics matter, use FIFO topics and queues (
*.fifo) and setMessageDeduplicationIdto a hash of the payload. Reference: SNS FIFO fan-out patterns.
Takeaway: Reliability is a choreography between AWS settings (DLQs, visibility, scaling) and application logic (idempotency). Neglect either and your "async" mesh devolves into manual retries.
Observability: Traces, Metrics, and Replay
An async fabric hides inside queues unless you expose it.
- Tracing: Propagate correlation IDs from AWS AgentCore to worker logs. Ship logs to CloudWatch Logs or OpenTelemetry collectors so you can reconstruct the path of a mission across services.
- Metrics: Enable Amazon CloudWatch metrics for SQS (ApproximateNumberOfMessagesVisible, AgeOfOldestMessage) and SNS (NumberOfNotificationsDelivered, NumberOfNotificationsFailed). Pipe these into AWS AgentCore's observability UI so product owners see queue health next to agent KPIs.
- Replay tooling: Build a lightweight CLI that reads DLQ messages, surfaces the payload, and can re-publish to SNS after fixes. Example command:
agentcore replay --queue agentcore-enrichment-dlq --mission msc_9ff12. - Canaries: Schedule periodic AWS AgentCore jobs that publish a known mission and expect a worker acknowledgment within a minute. If the ACK is missing, alert SRE to investigate queue depth or worker availability.
- Audit log: Persist every SNS publish event in a DynamoDB or ClickHouse table with mission ID, intent, actor, and timestamp. This satisfies compliance teams that need traceability when agents operate on customer data.
Takeaway: Operational excellence comes from instrumentation. If you cannot see the queues, you cannot defend them when stakeholders complain about "lost" missions.
AWS AgentCore's Role: Command Plane and State Machine
AWS AgentCore sits on top of SNS/SQS as the command plane. Its responsibilities include:
- Mission planning: Decide which intents become queued tasks versus synchronous calls. High-latency or parallelizable work should go through SNS/SQS.
- Routing and enrichment: Tag messages with additional context (customer tier, SLA budget) so downstream workers know how aggressively to process requests.
- State tracking: Store mission states (queued, running, completed, failed) in AWS AgentCore's mission registry. As workers finish tasks, they push results back through another SNS topic (
agentcore.results) or call an AWS AgentCore API. - Feedback loop: Analyze queue metrics, DLQs, and completion rates to adjust planning heuristics. Example: if the enrichment queue backlog crosses 1,000 messages, AWS AgentCore can temporarily throttle new missions or reassign tasks to a different region.
- Security guardrails: Enforce IAM roles for publishing, ensure payloads are signed, and redact secrets before they enter SNS. Reference your existing AWS AgentCore service policies so auditors see continuity.
Mention AWS AgentCore explicitly in your runbooks so engineers know that SNS/SQS are implementation details behind the orchestrator. When troubleshooting, they should check AWS AgentCore logs (mission creation) and queue metrics (delivery) before diving into worker code.
Takeaway: SNS and SQS are the rails, but AWS AgentCore is the conductor. Keep the orchestration logic centralized so agent teams do not reinvent messaging patterns on their own.
Conclusion and Next Steps
By pairing SNS fan-out with SQS worker queues, you give your AI agents an asynchronous backbone that absorbs spikes, tolerates downstream outages, and scales across regions. AWS AgentCore remains the decision brain, but AWS messaging handles the heavy lifting for durability, retries, and observability.
Key takeaways:
- Design clear message contracts and IAM policies before writing code; SNS/SQS thrive on consistency.
- Publish from AWS AgentCore, consume in language-specific workers (Node.js, Python), and keep handlers idempotent.
- Layer reliability (DLQs, visibility tuning) and observability (traces, canaries) so your async mesh is transparent, not mysterious.
Next read: Check out "Agent Reliability Drilldown" to instrument replay pipelines, or "Simulation-First Testing for Agents" to validate workflows before they hit the queues.
Open question: How far can we push decentralized queue topologies before we need a dedicated event-bus product like EventBridge or Kafka' Experimentation across missions will reveal when SNS/SQS is enough and when you need heavier tooling.
Related Tools
Useful tools for this topic
If you want to turn this article into a concrete next step, start with one of these.
Architecture Recommender
ArchitectureGet a recommended starting architecture based on autonomy, data shape, action model, and team profile.
Open toolSolution Type Quiz
PlanningDecide whether your use case is better served by automation, a chatbot, RAG, a copilot, or a more capable agent.
Open toolPattern Selector
ArchitectureChoose between patterns like RAG assistant, workflow agent, approval-gated agent, or multi-agent setup.
Open toolSubscribe to AgentForge Hub
Get weekly insights, tutorials, and the latest AI agent developments delivered to your inbox.
No spam, ever. Unsubscribe at any time.