Does Bigger Always Mean Better? Choosing the Right LLM for Agentic Workloads
Introduction
You’ve seen the benchmarks: more parameters mean higher scores. I fell into that trap—initially deploying a 175 B model for our internal customer-support agent, only to find page-long initialization delays and sky-high cloud bills. It wasn’t until I swapped in a 7 B model that I realized bigger isn’t always better, especially for agentic workloads where responsiveness and cost control matter as much as raw reasoning power.
In this article, we’ll unpack why model size alone is a poor proxy for performance, share real-world missteps, and equip you with a decision framework to pick the right foundation model for your autonomous agents.
Key Takeaway: Let your workload, not parameter count, drive your model choice.
Understanding Agentic Workloads
Agentic workloads combine several demands that most benchmarks ignore:
- Planning & orchestration: Breaking a goal into steps—research, synthesis, execution.
- Tool integration: Calling memory stores, APIs, or scrapers.
- Context management: Retaining multi-session state or user preferences.
- Real-time response: Meeting latency targets under load.
My Mistake: I once used a 13 B model for a voice assistant prototype and was devastated to see 300 ms jitter—users hung up before the response landed. I learned the hard way that average latency and variance both count.
Key Takeaway: Agentic tasks need balanced speed and capability; excessive latency breaks the experience.
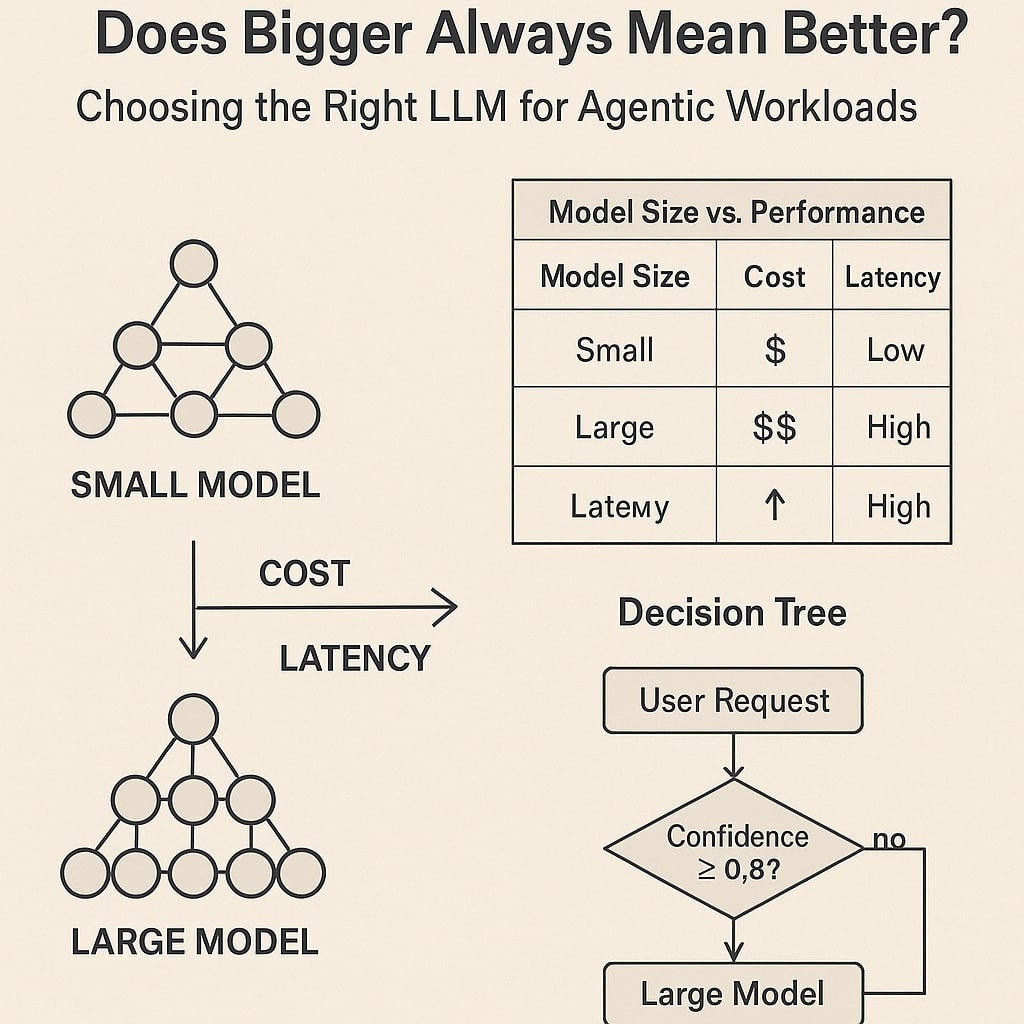
Model Size vs. Performance: The Trade-Off Matrix
Here’s a rough guide to what you’ll face as you scale up:
| Model Size | Latency (avg) | Cost per 1K tokens | Reasoning Strength |
|---|---|---|---|
| 2 B | ~50 ms | ~$0.001 | Low |
| 7 B | ~80 ms | ~$0.003 | Medium |
| 13 B | ~150 ms | ~$0.008 | Medium–High |
| 70 B | ~250 ms | ~$0.020 | High |
| 175 B | ~400 ms | ~$0.050 | Very High |
Insight: Beyond ~70 B, I saw only marginal gains in reasoning tests, but a 2× jump in cost and latency. It felt like paying luxury tax for a marginal IQ boost.
Key Takeaway: Plot latency and cost curves alongside reasoning benchmarks—don’t assume linear improvements.
When Bigger Models Win
Large models are indispensable when accuracy and depth matter:
- Complex reasoning: Multi-hop logic, intricate code generation, or legal contract analysis.
- High-stakes domains: Medical advice, compliance checks where errors are unacceptable.
Real Example: At one project, our 13 B model misinterpreted a compliance rule and generated an incorrect audit summary. Switching to 70 B eliminated those errors—but we isolated the higher cost to only those critical audit paths.
Key Takeaway: Use larger models selectively for critical tasks where mistakes carry real penalties.
When Smaller Models Shine
Smaller models often outperform their larger siblings in production:
- Low-latency needs: Chatbots, voice assistants, edge inference demand sub-100 ms responses.
- Budget constraints: High QPS (queries per second) can blow budgets if you over-index on size.
Lesson Learned: We once budgeted for 175 B inference across 50 K daily queries—our first month’s invoice was triple projections. Downgrading to 7 B saved 75 % of cost with negligible drop in user satisfaction.
Key Takeaway: If your SLA is response time or cost-driven, start small and only scale up where you hit accuracy ceilings.
Hybrid & Dynamic Strategies
You don’t have to pick one model for all tasks:
-
Cascade architectures
- First pass: Run a fast, small model.
- Second pass: Escalate to a larger model if confidence is low.
-
Distillation & fine-tuning
- Create a bespoke mid-tier model (e.g., 13 B distilled from 70 B) that captures essential capabilities at lower cost.
Experiment: For our internal helpdesk, we used a 7 B model for FAQs and escalated to 70 B for unresolved tickets. That combo cut average latency by 40 % and reduced 70 B calls to just 15 % of volume.
Key Takeaway: Dynamic routing lets you optimize cost and performance per request.
Decision Framework: Matching Models to Workloads
Use this five-step checklist to find your sweet spot:
-
Define constraints
- Latency target (e.g., <100 ms)
- Budget cap (e.g., <$1,000/month)
-
Assess complexity
- Low (simple Q&A)
- Medium (structured extraction)
- High (multi-hop reasoning, code synthesis)
-
Prototype & benchmark
- Compare small (7 B) vs. large (70 B) on sample prompts.
- Measure latency, cost, and accuracy under expected load.
-
Analyze & choose
- If small model meets targets, lock it in.
- If not, adopt a cascade or larger model.
-
Implement fallback
- Add a confidence threshold to route tricky cases to the bigger model.
flowchart LR
A[User Request] --> B{Confidence ≥ 0.8?}
B -- Yes --> C[7B Model]
B -- No --> D[70B Model]
C --> E[Return Response]
D --> E
Personal Tip: Automate your benchmarks in CI—run them daily as model versions update, so you never get bit by a silent performance regression.
Key Takeaway: Data-driven benchmarking beats guesswork every time.
Conclusion
In the agentic era, match your model’s capabilities to your constraints:
- Define your latency and budget up front
- Test across at least two model sizes
- Embrace hybrid strategies for optimal ROI
By steering clear of parameter-centric thinking and focusing on real-world metrics, you’ll deliver agile, cost-effective agents that delight users—and keep your finance team happy.
Final Thought: Bigger models have their place, but smarter selection wins the day.
Further Reading & Resources
- MLPerf Inference Benchmarks
- Hugging Face Model Leaderboards
- “Model Context Protocol: Landscape, Security, and Best Practices” (2025 Survey)
- TechRepublic’s Agentic AI Hub
Related Tools
Useful tools for this topic
If you want to turn this article into a concrete next step, start with one of these.
Complexity Estimator
PlanningEstimate how much build and operational complexity a proposed AI system is likely to create.
Open toolROI Calculator
PlanningEstimate time savings, cost impact, and likely business value before committing to a build.
Open toolSolution Type Quiz
PlanningDecide whether your use case is better served by automation, a chatbot, RAG, a copilot, or a more capable agent.
Open toolSubscribe to AgentForge Hub
Get weekly insights, tutorials, and the latest AI agent developments delivered to your inbox.
No spam, ever. Unsubscribe at any time.