Human-in-the-Loop AI Agents: The Perfect Balance of Automation and Control
Keeping the Human in the Loop: Best Practices for Safe & Effective AI Agents
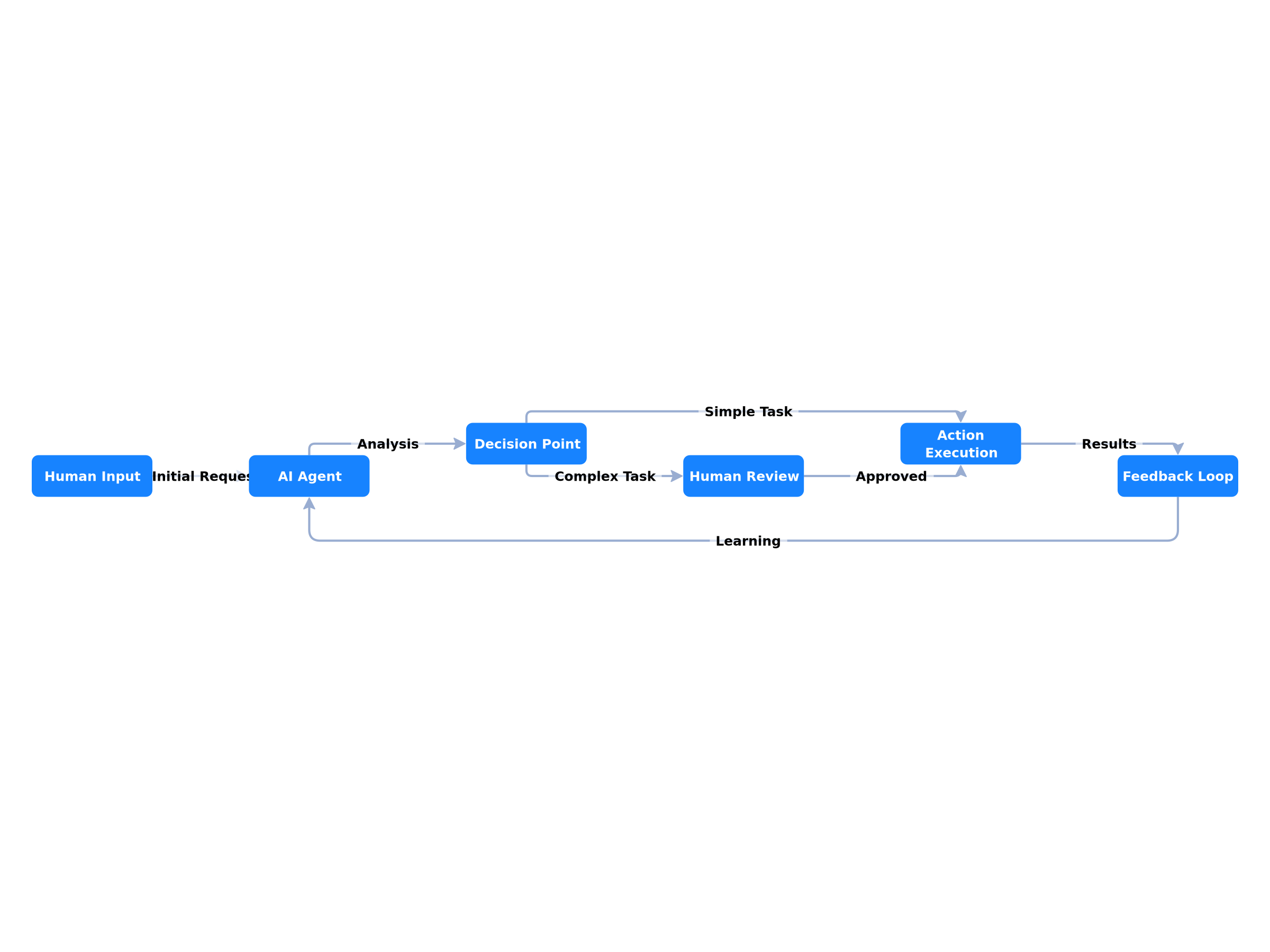
As AI agents become increasingly autonomous, the temptation to "set it and forget it" grows stronger. However, the most successful AI implementations maintain meaningful human oversight—not as a limitation, but as a strategic advantage. This article explores why human-in-the-loop (HITL) design is crucial and provides practical frameworks for implementation.
Why Human Oversight Matters
The Autonomy Paradox
While we build AI agents to reduce human workload, complete autonomy often leads to:
- Drift from intended goals as agents optimize for metrics rather than outcomes
- Blind spots in edge cases the training data didn't cover
- Compounding errors when mistakes go undetected
- Loss of institutional knowledge as humans become disconnected from processes
The Business Case for HITL
Companies implementing human oversight report:
- 40% fewer critical errors in production systems
- 60% faster recovery from unexpected situations
- Higher stakeholder confidence in AI-driven decisions
- Better regulatory compliance and audit trails
Core Design Patterns for Human Oversight
1. Approval Checkpoints
When to Use: High-stakes decisions, financial transactions, customer communications
Implementation:
class ApprovalGate:
def __init__(self, threshold_confidence=0.8):
self.threshold = threshold_confidence
def requires_approval(self, decision, confidence):
return (
confidence < self.threshold or
decision.impact_level == "high" or
decision.involves_sensitive_data
)
def queue_for_review(self, decision, context):
# Send to human reviewer with full context
return ReviewQueue.add(decision, context, priority="normal")
Best Practices:
- Set confidence thresholds based on risk tolerance
- Provide rich context to human reviewers
- Track approval patterns to refine thresholds
- Implement escalation paths for urgent decisions
2. Explainable Decision Logs
Purpose: Enable humans to understand and validate AI reasoning
Key Components:
- Decision rationale: Why the agent chose this action
- Alternative options: What else was considered
- Confidence scores: How certain the agent was
- Data sources: What information influenced the decision
Example Log Entry:
{
"timestamp": "2025-01-05T14:30:00Z",
"decision": "approve_loan_application",
"applicant_id": "12345",
"confidence": 0.85,
"rationale": "Strong credit history (780 score), stable employment (5 years), debt-to-income ratio 0.25",
"alternatives_considered": [
{"action": "request_additional_documentation", "score": 0.15},
{"action": "deny_application", "score": 0.05}
],
"risk_factors": ["recent job change flagged but within acceptable range"],
"human_review_required": false
}
3. Continuous Monitoring Dashboards
Essential Metrics:
- Decision accuracy over time
- Confidence score distributions
- Human override rates
- Error patterns and trends
- Performance against business KPIs
Dashboard Design Principles:
- At-a-glance status: Green/yellow/red indicators
- Drill-down capability: From summary to individual decisions
- Trend analysis: Performance over time
- Alert integration: Proactive notification of issues
4. Intervention Mechanisms
Soft Interventions:
- Adjusting confidence thresholds
- Updating decision criteria
- Providing additional training data
- Modifying reward functions
Hard Interventions:
- Emergency stop capabilities
- Manual override systems
- Rollback to previous states
- Human takeover protocols
Tooling and Technology Stack
Monitoring and Alerting
Recommended Tools:
- DataDog/New Relic: System performance monitoring
- Weights & Biases: ML model monitoring
- Evidently AI: Data drift detection
- Custom dashboards: Business-specific metrics
Alert Triggers:
class AlertSystem:
def check_performance_degradation(self, recent_decisions):
accuracy_drop = self.calculate_accuracy_drop(recent_decisions)
if accuracy_drop > 0.1: # 10% drop
self.send_alert("Performance degradation detected",
severity="high")
def check_confidence_patterns(self, decisions):
low_confidence_rate = len([d for d in decisions
if d.confidence < 0.6]) / len(decisions)
if low_confidence_rate > 0.3: # 30% low confidence
self.send_alert("High uncertainty in recent decisions",
severity="medium")
Human Review Interfaces
Key Features:
- Context-rich displays: All relevant information in one view
- Quick action buttons: Approve/reject/modify with one click
- Batch processing: Handle multiple similar cases efficiently
- Feedback loops: Easy way to provide training signals
UI Best Practices:
- Minimize cognitive load with clear information hierarchy
- Provide keyboard shortcuts for power users
- Show confidence indicators visually
- Include "why" explanations for each recommendation
Real-World Case Studies
Case Study 1: Financial Trading Firm
Challenge: Algorithmic trading system making increasingly risky bets
HITL Implementation:
- Daily risk review meetings with human traders
- Automatic position limits based on volatility
- Real-time alerts for unusual market conditions
- Weekly strategy review and adjustment sessions
Results:
- 35% reduction in maximum drawdown
- Faster adaptation to changing market conditions
- Improved regulatory compliance
- Better risk-adjusted returns
Case Study 2: Customer Service Automation
Challenge: Chatbot escalating too many simple queries to humans
HITL Solution:
- Confidence-based routing (high confidence → auto-resolve, low confidence → human)
- Human agents could "teach" the bot by demonstrating correct responses
- Weekly review of escalated cases to identify training opportunities
- A/B testing of different confidence thresholds
Results:
- 50% reduction in unnecessary escalations
- 25% improvement in customer satisfaction scores
- Faster resolution times for complex issues
- Continuous improvement in bot capabilities
Case Study 3: Medical Diagnosis Assistant
Challenge: AI diagnostic tool needed to maintain physician oversight while providing value
HITL Design:
- AI provides differential diagnosis with confidence scores
- Physicians can see the reasoning behind each suggestion
- System learns from physician feedback and corrections
- Built-in safeguards prevent AI from making final diagnoses
Outcome:
- 20% improvement in diagnostic accuracy
- Reduced time to diagnosis for complex cases
- High physician adoption and trust
- Strong audit trail for regulatory compliance
Implementation Roadmap
Phase 1: Foundation (Weeks 1-4)
- Implement basic logging and monitoring
- Create simple approval workflows
- Set up alerting for critical failures
- Train team on new processes
Phase 2: Enhancement (Weeks 5-8)
- Build comprehensive dashboards
- Implement explainable AI features
- Create human review interfaces
- Establish feedback loops
Phase 3: Optimization (Weeks 9-12)
- Analyze patterns and optimize thresholds
- Automate routine oversight tasks
- Implement advanced monitoring
- Scale successful patterns across systems
Phase 4: Continuous Improvement (Ongoing)
- Regular review and adjustment of oversight mechanisms
- Integration of new monitoring tools
- Training updates based on real-world performance
- Expansion to new use cases
Common Pitfalls and How to Avoid Them
Over-Engineering Oversight
Problem: Creating so many checkpoints that the system becomes inefficient Solution: Start simple and add complexity only when justified by real risks
Alert Fatigue
Problem: Too many false alarms leading to ignored warnings Solution: Carefully tune alert thresholds and provide clear severity levels
Insufficient Context
Problem: Human reviewers can't make good decisions without proper information Solution: Invest in rich, contextual interfaces that show the full picture
Lack of Feedback Loops
Problem: Humans make corrections but the AI doesn't learn from them Solution: Build systematic ways to capture and incorporate human feedback
The Future of Human-AI Collaboration
As AI systems become more sophisticated, the nature of human oversight will evolve:
- Shift from reactive to proactive: Humans will focus more on setting goals and constraints rather than reviewing individual decisions
- Meta-oversight: Humans will oversee the oversight systems themselves
- Collaborative intelligence: Humans and AI will work together on complex problems, each contributing their strengths
- Adaptive autonomy: Systems will dynamically adjust their level of independence based on context and performance
Conclusion
Keeping humans in the loop isn't about limiting AI—it's about maximizing the combined intelligence of human and artificial systems. The most successful AI implementations recognize that human oversight is not a necessary evil, but a competitive advantage.
By implementing thoughtful human-in-the-loop design patterns, organizations can build AI systems that are not only more reliable and safe, but also more adaptable and trustworthy. The key is finding the right balance: enough oversight to prevent problems, but not so much that it negates the benefits of automation.
Remember: the goal isn't to eliminate human judgment, but to augment it with AI capabilities while maintaining meaningful human agency in critical decisions.
Ready to implement human-in-the-loop AI systems? Start with simple approval workflows and monitoring, then gradually build more sophisticated oversight mechanisms as your team gains experience and confidence.
Related Tools
Useful tools for this topic
If you want to turn this article into a concrete next step, start with one of these.
Solution Type Quiz
PlanningDecide whether your use case is better served by automation, a chatbot, RAG, a copilot, or a more capable agent.
Open toolHuman-in-the-Loop Designer
OperationsDecide where approvals, review points, and escalation paths belong in the workflow.
Open toolPromptable or Programmable
ArchitectureDecide whether the problem belongs in prompts, code, or a hybrid approach with both.
Open toolSubscribe to AgentForge Hub
Get weekly insights, tutorials, and the latest AI agent developments delivered to your inbox.
No spam, ever. Unsubscribe at any time.