Tuning Small LLMs for Fast, Tool-Using Agents: Qwen3-4B + Ollama + Strands (with Rationale)

Tuning Small LLMs for Fast, Tool-Using Agents: Qwen3-4B + Ollama + Strands (with Rationale)
Thesis: With the right guardrails, a tiny model can feel like a pro—fast to first token, decisive with tools, and brief with words. This version explains why each step exists and what value it brings in production.
Most builders scale up model size when the app feels sluggish. That works, but it’s expensive and hides a deeper truth: latency and reliability often come from orchestration, not raw parameter count. Below, we show how to make Qwen3‑4B (via Ollama) act like a disciplined operator inside Strands—quick tool calls, minimal rambling, and production‑friendly outputs—and we annotate every decision with the rationale.
TL;DR
- Keep the model on a short leash: strict stops, tiny max tokens, JSON‑only tool turns.
Why: Reduces rambling and parsing errors—your runtime becomes predictable. - Make tool turns deterministic (temperature 0.0) and final turns concise (≤ 120 tokens).
Why: Tool invocations must be stable; user answers should be crisp to conserve time and tokens. - Route lightly: at most one clarify turn; otherwise call the tool or answer.
Why: Fewer hops = lower latency and fewer failure points. - Measure what matters: first‑token, tool‑selection accuracy, answer length.
Why: These three metrics track UX speed, reliability, and verbosity.
Architecture at a glance
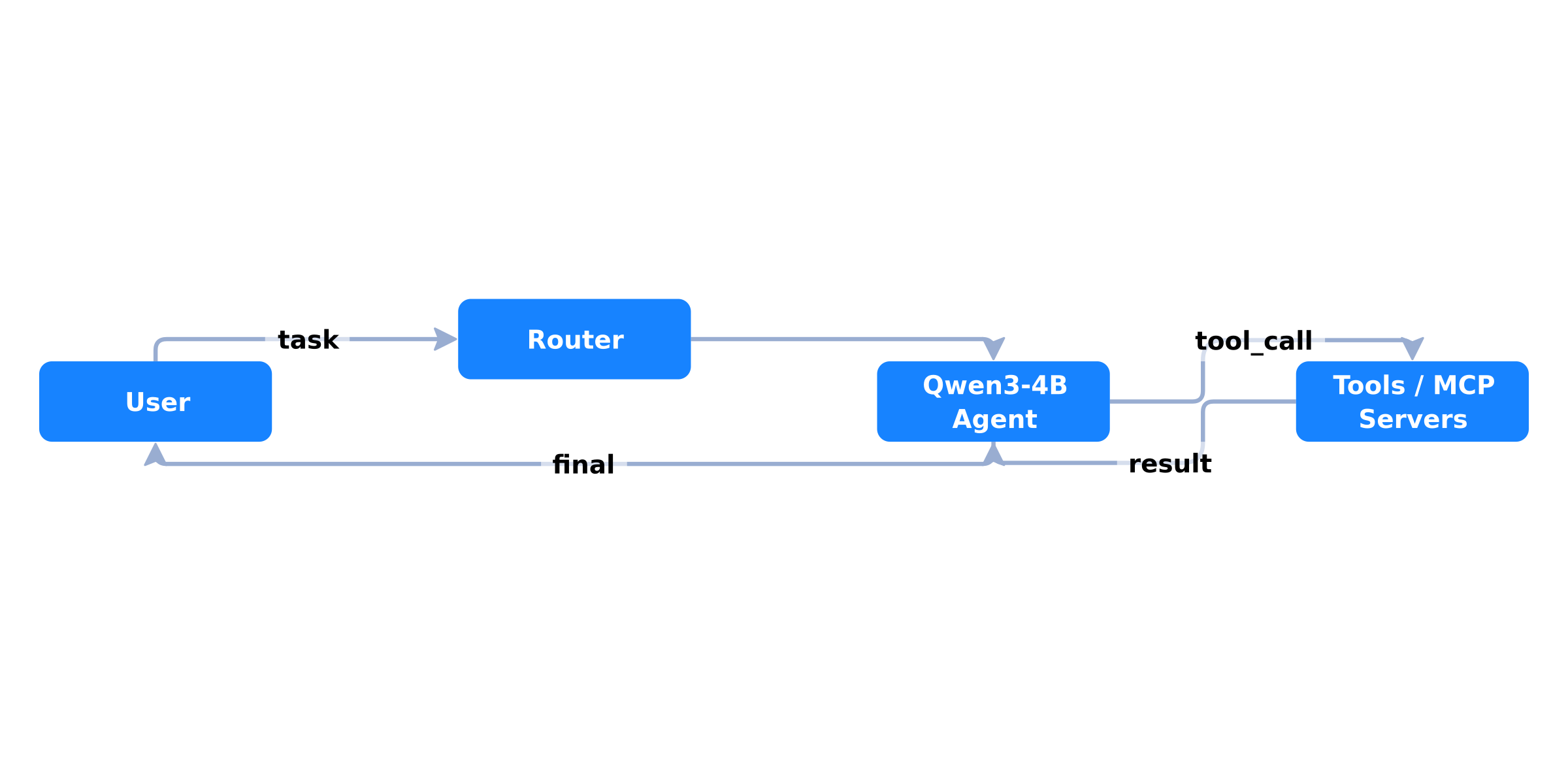
Why this shape?
- Value: Minimizes orchestrator complexity. The router either forwards or asks one clarifying question; the worker agent either answers or calls a tool. Fewer states make timeouts/retries and observability simpler.
Prerequisites (and why they matter)
- Ollama installed and
qwen3:4bpulled.
Value: Local inference keeps marginal costs near zero and enables offline dev. - A Strands project (JSON agent schema below).
Value: Gives you per‑turn decoding control and a clean place to mount tools. - Optional: MCP servers (filesystem/browser/vector).
Value: Lets a small model extend its reach with structured, auditable capabilities.
Ollama options for low‑latency discipline
{
"num_ctx": 4096,
"temperature": 0.2,
"top_p": 0.9,
"top_k": 40,
"mirostat": 0,
"repeat_penalty": 1.05,
"stop": ["</tool_call>", "</final>"],
"num_thread": "auto"
}
Why these settings?
- temperature 0.2: Keeps wording stable on planning turns without sounding robotic.
- temperature 0.0 (tool turns): Guarantees deterministic JSON; fewer malformed calls.
- repeat_penalty 1.05: Nudge to avoid loops; stronger penalties can hurt recall.
- explicit stop tokens: Hard stop is safer than hoping the model “knows” when to end.
- num_thread auto: Uses available cores without hand‑tuning on most dev boxes.
Value: These choices trade a bit of creativity for predictable control, which is what you need for tool reliability and low latency.
Prompt scaffolds (copy‑paste) with rationale
System prompt (tool‑first, brevity‑biased)
You are a production agent. Prefer calling tools when available.
Keep thoughts terse (≤ 2 short lines). Never explain internal reasoning.
If a tool is needed, emit exactly ONE tool_call JSON and stop.
If the question is trivial, answer directly in ≤ 3 sentences.
Why this wording?
- “Production agent” frames priorities: correctness and brevity over eloquence.
- “ONE tool_call” prevents tool‑call spam; pairs with stop tokens for hard bounds.
- “Trivial → direct answer” reduces over‑tooling (faster for easy tasks).
Tool‑call contract (strict JSON)
<tool_instructions>
Return JSON only:
{ "name": string, "arguments": object }
Do not add commentary.
</tool_instructions>
Why: Constrains the surface area you must parse. Value: Fewer exceptions, simpler adapters.
Strands agent definitions (and why this structure)
Your schema:
{
"name": "qwen4b-tools",
"description": "Fast tool-first agent using Qwen3-4B on Ollama",
"model": "ollama:qwen3:4b",
"system_prompt": "You are a production agent. Prefer calling tools...",
"tools": ["search", "http_get", "file_write"],
"defaults": { "schedule": [] },
"tags": ["fast", "local", "tooling"],
"session_strategy": "new"
}
Why these choices?
- One worker agent: Reduces orchestration branches.
- Minimal tool set: Start with 2–3 high‑value tools to keep evaluation simple.
- session_strategy: new: Avoids cross‑task memory bleed while you tune behavior.
Optional lightweight router:
{
"name": "router-lite",
"description": "Minimal router that either forwards or asks one clarifying question",
"model": "ollama:qwen3:4b",
"system_prompt": "Route to qwen4b-tools or ask ONE concise clarifying question. Never think out loud.",
"tools": [],
"defaults": { "schedule": [] },
"tags": ["router"],
"session_strategy": "new"
}
Why a tiny router?
- Value: Lets you catch ambiguous prompts without spawning a plan tree. Keeps latency budget intact and metrics readable.
Turn‑type decoding settings (and the value they deliver)
| Turn | temp | max_tokens | stop | Value delivered |
|---|---|---|---|---|
| Plan/route | 0.2 | 128 | </final> |
Short, decisive routing—prevents chain sprawl |
| Tool call | 0.0 | 128 | </tool_call> |
Deterministic JSON—no parser glue code |
| Final | 0.3 | 256 | </final> |
Crisp answers—predictable token spend |
Why table stakes? Per‑turn controls are the single most effective way to make small models feel “senior” in production.
Quick evaluation harness (latency + accuracy) and why to track it
Save as eval_qwen_tools.py and wire run_once() to your Strands endpoint.
import time, json
from collections import defaultdict
from client import run_once # you implement this
CASES = [
{"id":"calc","q":"What is 17*23? Use the calc tool.","expect_tool":"calc"},
{"id":"http","q":"Fetch the title of https://example.com via http_get.","expect_tool":"http_get"},
{"id":"final","q":"Define idempotency in one sentence.","expect_tool":None}
]
def main():
results = []
for c in CASES:
t0 = time.time()
out = run_once(c["q"]) # -> { "tool_name": str|None, "final_text": str, "used_tool": bool }
dt = time.time() - t0
ok_tool = (out.get("tool_name") == c["expect_tool"])
results.append({"id":c["id"], "latency_s": round(dt,3), "ok_tool": ok_tool, "len_final": len(out.get("final_text","").split())})
print(json.dumps(results, indent=2))
if __name__ == "__main__":
main()
Why these metrics?
- latency_s: UX responsiveness. Users perceive “instant” under ~1s.
- ok_tool: Reliability of the tool policy. If low, fix prompts/decoding before adding tools.
- len_final: Keeps answers terse and scannable; prevents runaway token use.
Targets
- First token < 500ms on a decent desktop
- Tool selection accuracy ≥ 0.9 on your core set
- Final answers ≤ 120 words
Troubleshooting playbook with root‑cause intent
“The model thinks too long.”
- Lower max_tokens on plan/tool turns; add hard stop tokens.
- Add “≤ 2 short lines of thought” rule.
Why/Value: Caps compute + variance; surfaces true tool time.
“Tool JSON is messy.”
- Force temperature: 0.0 on tool turns; embed JSON schema; stop on
</tool_call>.
Why/Value: Determinism reduces adapter code and flaky tests.
“It over‑tools simple questions.”
- Add “If trivial, answer directly” to system; lightweight router to gate tools.
Why/Value: Latency win on easy tasks; better perceived intelligence.
“Latency spikes randomly.”
- Preload model (
keep_alive), pin threads, cap retries.
Why/Value: Smoother tail latency; more predictable SLOs.
What a small but tool‑using agent can actually do
A 4B model won’t write a research paper solo—but paired with tools it becomes a capable operator. Here are high‑value patterns that work well at 4B, plus why they shine:
-
Structured web/API fetch + transform
- Do: Call HTTP/search tools, extract titles/metadata, summarize briefly.
- Value: Deterministic pipelines; model only orchestrates and compresses.
-
Calculations & data shaping
- Do: Offload math to a
calctool; reshape CSV/JSON with simple rules. - Value: Tools guarantee correctness; model focuses on intent mapping.
- Do: Offload math to a
-
File I/O and templating
- Do: Draft README snippets, config stubs, or test scaffolds via
file_write. - Value: Fast scaffolding beats creative prose; keeps outputs consistent.
- Do: Draft README snippets, config stubs, or test scaffolds via
-
CLI/DevOps macros (guardrailed)
- Do: Generate and explain safe shell commands; execute via a controlled runner.
- Value: Accelerates mundane ops; your runner enforces safety policies.
-
Retrieval‑augmented lookups
- Do: Query a vector store for known docs, then answer in ≤ 120 words with citations.
- Value: Knowledge comes from your corpus; model just stitches context.
-
Light planning & routing
- Do: Choose between “answer directly” vs “call X tool,” ask one clarify question max.
- Value: Keeps chains tight; great UX without heavy reasoning.
-
Monitoring & status explainers
- Do: Read metrics/logs via API, classify status, produce a one‑paragraph summary.
- Value: Opinionated executive summaries—fast and useful.
Limitations (and mitigations)
- Long reasoning chains: Avoid; use tools or escalate to a bigger model for “deep mode.”
- Ambiguous prompts: Use the router’s single clarify question.
- Creative drafting: Keep to outlines/templates; let humans polish.
Why this approach is interesting
Speed makes new UX possible: interactive shells, live coding assistants, real‑time dashboards—all benefit more from responsiveness than raw IQ. A disciplined 4B that answers in 400–800ms feels magical and unlocks product loops that a 20‑second genius never will. You’re not dumbing things down; you’re tightening the feedback loop so users stay in flow. When you do need depth, flip a feature flag to a larger model—the orchestration remains the same.
Next steps (and the value of each)
- Add MCP servers (filesystem, browser, vector); re‑run the eval.
Value: Expands action space without growing params. - Introduce a latency budget per turn with polite aborts.
Value: Guarantees snappy UX even under load. - Publish a follow‑up comparing qwen3:4b vs 7B under identical settings.
Value: Gives readers a fair “cost for reliability” chart they can replicate.
Appendix: One‑file Strands task (pseudo)
{
"name": "qwen4b-tools",
"description": "Fast tool-first agent using Qwen3-4B on Ollama",
"model": "ollama:qwen3:4b",
"system_prompt": "You are a production agent. Prefer calling tools when available...",
"tools": ["calc", "http_get", "search"],
"defaults": { "schedule": [] },
"tags": ["fast","local","tooling"],
"session_strategy": "new"
}
Related Tools
Useful tools for this topic
If you want to turn this article into a concrete next step, start with one of these.
Solution Type Quiz
PlanningDecide whether your use case is better served by automation, a chatbot, RAG, a copilot, or a more capable agent.
Open toolArchitecture Recommender
ArchitectureGet a recommended starting architecture based on autonomy, data shape, action model, and team profile.
Open toolEvaluation Plan Builder
OperationsBuild a first evaluation plan for answer quality, action safety, human review, monitoring, and rollback.
Open toolSubscribe to AgentForge Hub
Get weekly insights, tutorials, and the latest AI agent developments delivered to your inbox.
No spam, ever. Unsubscribe at any time.